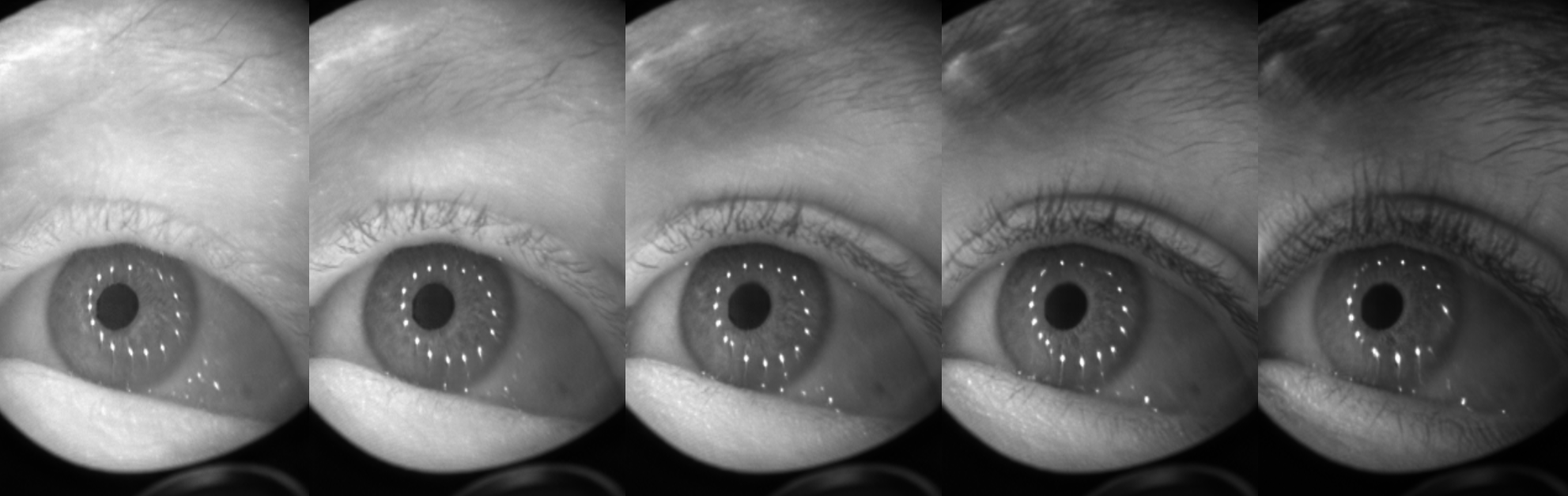
Walking the style latent space in our proposed method, Seg2Eye. We extract latent style codes from two people and show the decodings of their linear interpolation.
Abstract
Accurately labeled real-world training data can be scarce, and hence recent works adapt, modify or generate images to boost target datasets. However, retaining relevant details from input data in the generated images is challenging and failure could be critical to the performance on the final task. In this work, we synthesize person-specific eye images that satisfy a given semantic segmentation mask (content), while following the style of a specified person from only a few reference images. We introduce two approaches, (a) one used to win the OpenEDS Synthetic Eye Generation Challenge at ICCVW 2019, and (b) a principled approach to solving the problem involving simultaneous injection of style and content information at multiple scales. Our implementation is available on GitHub.
Acknowledgments
This work was supported in part by the ERC Grant OPTINT (StG-2016-717054).