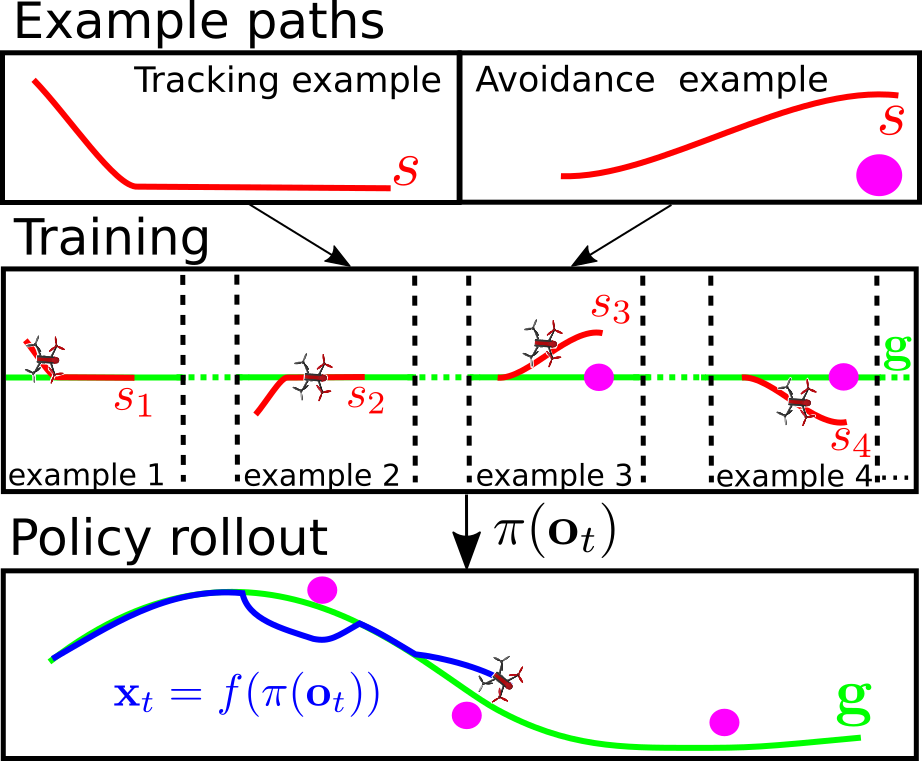
A policy is learned from few, short local collision avoidance and path following maneuvers (red). The learned policy generalizes to unseen scenes and can track long guidance paths (green) through complex environments while successfully avoiding obstacles (blue).
Abstract
In this paper we propose an algorithm for the training of neural network control policies for quadrotors. The control policy computes control commands directly from sensor inputs. The algorithm uses imitation learning principles to produce the policy that reproduces a supervisor behavior. The supervisor provides demonstration how to follow the global path and perform collision avoidance maneuvers. We leverage the neural network ability to generalize by learning from different examples. The resulting policy performs local collision avoidance while following a global reference path. The algorithm uses a time-free model predictive path-following controller as a supervisor. The controller generates demonstrations by following example paths. This enables an easy to implement learning algorithm that is robust to errors of the model used in the model predictive controller. The policy is trained on the real quadrotor, which requires collision-free exploration around the example path. An adapted version of the supervisor is used to enable exploration. Thus, the policy can be trained from a relatively small number of examples on the real quadrotor, making the training sample efficient.
Video
Acknowledgments
This work was supported in part by the Swiss National Science Foundation (UFO 200021L_153644) and in part by the NWO Domain Applied Sciences.