
Quadrotor camera tools generate trajectories based on user-specified keyframes in time and space. Reasoning about spatio-temporal distances is hard for users and can lead to visually unappealing results and fluctuating camera velocities. Top row: user-specified keyframes (blue) are positioned in time, such that the camera first moves too slow and then needs to accelerate drastically to reach the specified end-point. Bottom row: results of our method which automatically positions keyframes (blue) in time such that the camera moves smoothly over the entire trajectory (illustrative example).
Abstract
In this paper we first contribute a large scale online study (N≈400) to better understand aesthetic perception of aerial video. The results indicate that it is paramount to optimize smoothness of trajectories across all keyframes. However, for experts timing control remains an essential tool. Satisfying this dual goal is technically challenging because it requires giving up desirable properties in the optimization formulation. Second, informed by this study we propose a method that optimizes positional and temporal reference fit jointly. This allows to generate globally smooth trajectories, while retaining user control over reference timings. The formulation is posed as a variable, infinite horizon, contour-following algorithm. Finally, a comparative lab study indicates that our optimization scheme outperforms the state-of-the-art in terms of perceived usability and preference of resulting videos. For novices our method produces smoother and better looking results and also experts benefit from generated timings.
Accompanying Video
Additional Results
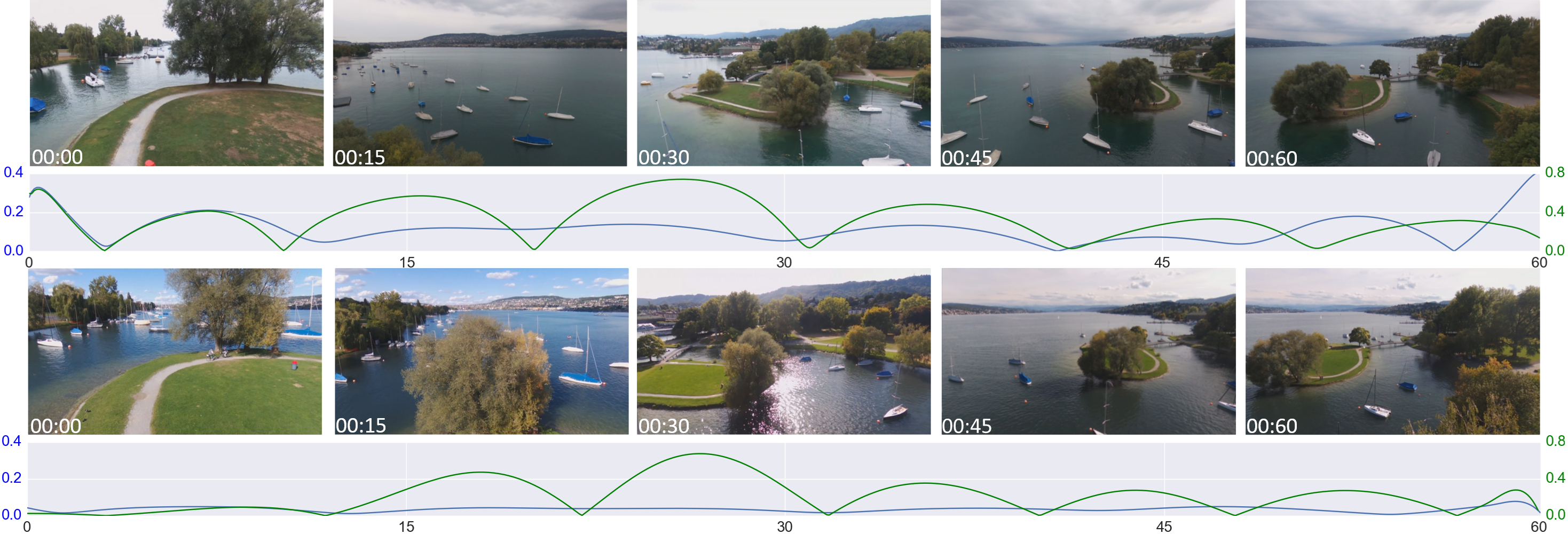
Qualitative comparison of video frames as well as jerk and angular jerk profiles of two trajectories generated with [Gebhardt et al. 2016] (top row) and our method (bottom row).
Acknowledgments
We thank Yi Hao Ng for his work in the exploratory phase of the project, Chat Wacharamanotham for helping with the statistical analysis of the perceptual study and Velko Vechev for providing the video voice-over. We are also grateful for the valuable feedback of Tobias Nägeli on problem formulation and implementation. This work was funded in parts by the Swiss National Science Foundation (UFO 200021L_153644).