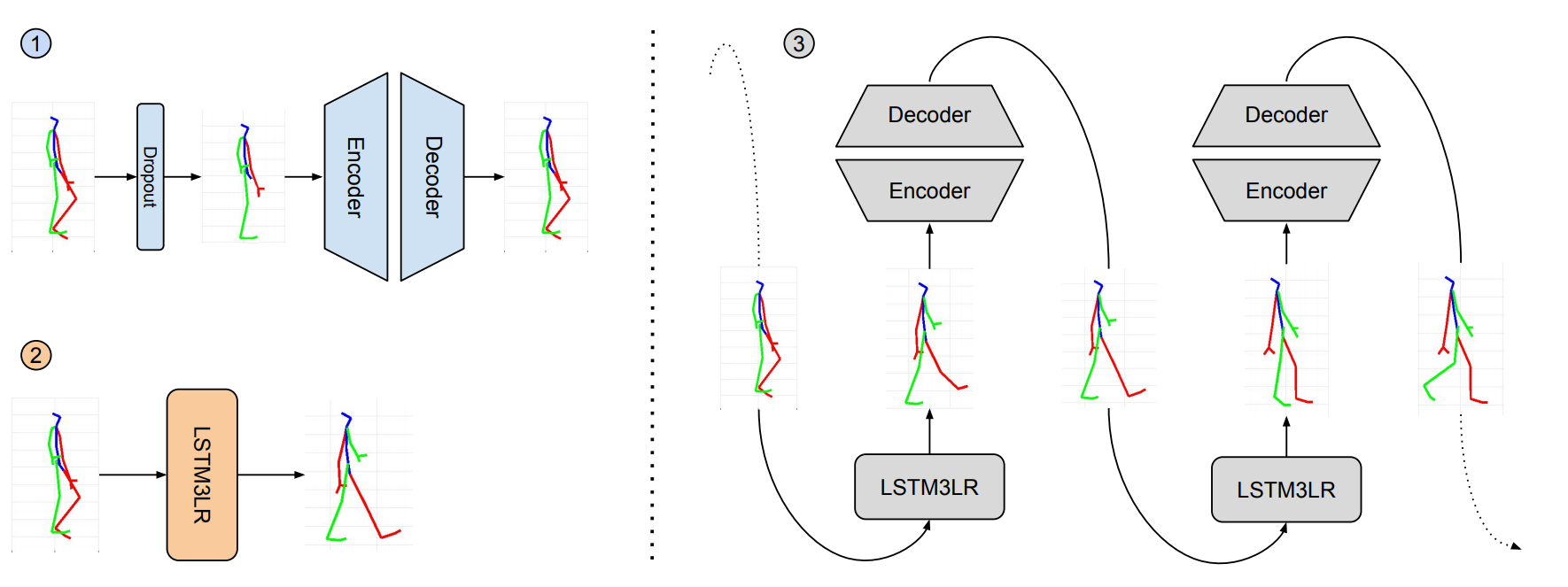
Schematic overview over the proposed method. (1) A variant of de-noising autoencoders learns the spatial configuration of the
human skeleton via training with dropouts, removing entire joints at random which have to be reconstructed by the network. (2) We train
a 3-layer LSTM recurrent neural network to predict skeletal configurations over time. (3) At inference time both components are stacked
and the dropout autoencoder filters the noisy predictions of the LSTM layers, preventing accumulation of error and hence pose drift over
time.
</p>
We propose a new architecture for the learning of predictive
spatio-temporal motion models from data alone. Our
approach, dubbed the Dropout Autoencoder LSTM (DAE-LSTM),
is capable of synthesizing natural looking motion
sequences over long-time horizons1 without catastrophic
drift or motion degradation. The model consists of two components,
a 3-layer recurrent neural network to model temporal
aspects and a novel autoencoder that is trained to
implicitly recover the spatial structure of the human skeleton
via randomly removing information about joints during
training. This Dropout Autoencoder (DAE) is then used
to filter each predicted pose by a 3-layer LSTM network,
reducing accumulation of correlated error and hence drift
over time. Furthermore to alleviate insufficiency of commonly
used quality metric, we propose a new evaluation
protocol using action classifiers to assess the quality of synthetic
motion sequences. The proposed protocol can be used
to assess quality of generated sequences of arbitrary length.
Finally, we evaluate our proposed method on two of the
largest motion-capture datasets available and show that our
model outperforms the state-of-the-art techniques on a variety
of actions, including cyclic and acyclic motion, and
that it can produce natural looking sequences over longer
time horizons than previous methods.
1 > 10s for periodic motions, e.g. walking, > 2s for aperiodic motion, e.g. eating
Abstract
Video