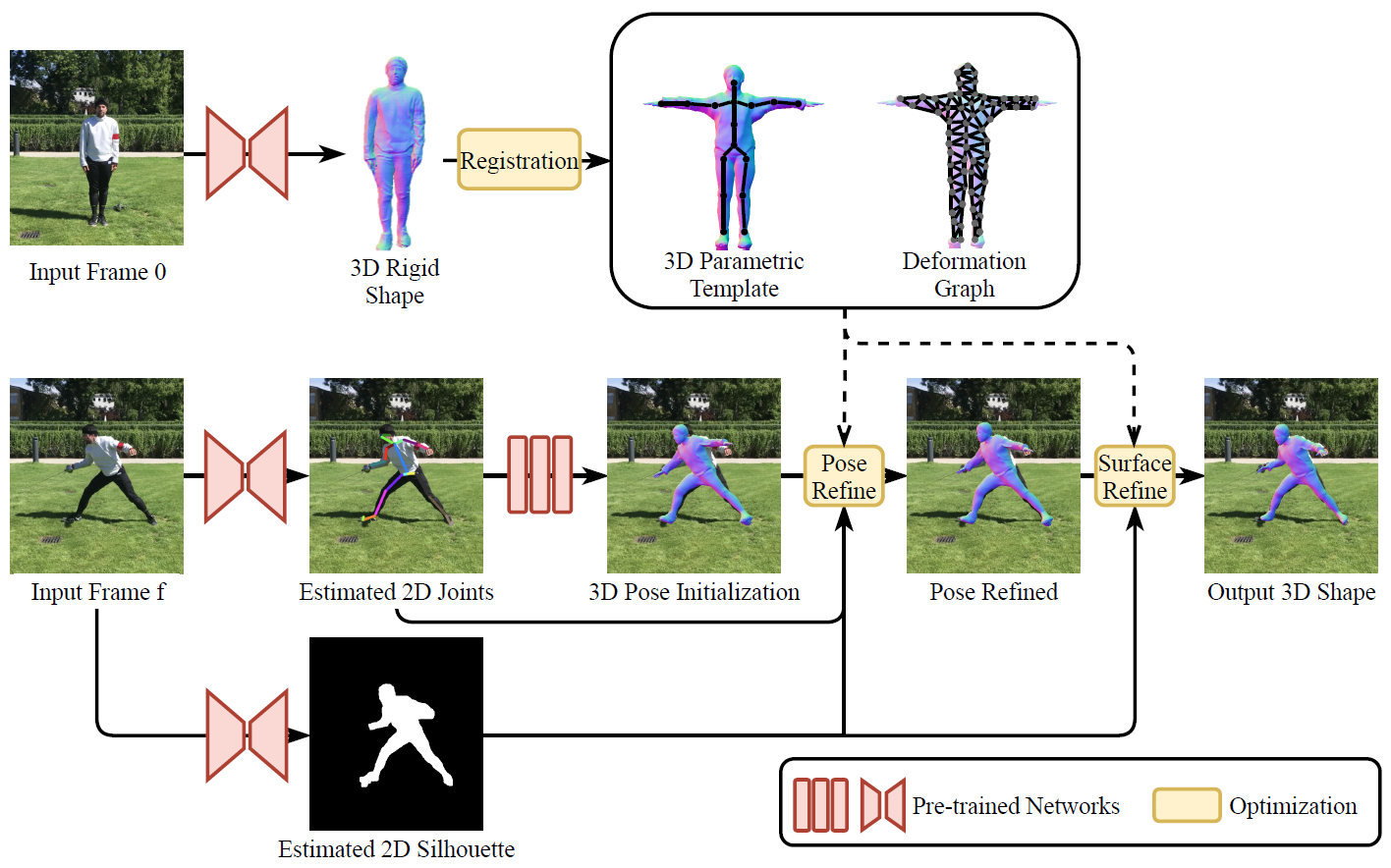
Method overview: Given a monocular video as input, a parametric template model is automatically constructed from the initial frame of the video. We reconstruct the rigid 3D shape using the state-of-the-art single view reconstruction method. We then register a generic human model SMPL onto the rigid shape to build the parametric template with an embedded deformation graph. To reconstruct the dynamically deforming 3D surface at each frame, we optimize the pose, shape, and surface deformation parameters of the template to image observations. We first extract 2D joints and silhouettes from the RGB image. From 2D joints, we estimate 3D body poses to initialize the pose parameter. After initialization, we optimize the pose parameters by aligning the template with the 2D joints and silhouette. Afterward, we further optimize the detailed surface deformation by silhouette alignment.
Abstract
Capturing the dynamically deforming 3D shape of clothed human is essential for numerous applications, including VR/AR, autonomous driving, and human-computer interaction. Existing methods either require a highly specialized capturing setup, such as expensive multi-view imaging systems, or they lack robustness to challenging body poses. In this work, we propose a method capable of capturing the dynamic 3D human shape from a monocular video featuring challenging body poses, without any additional input. We first build a 3D template human model of the subject based on a learned regression model. We then track this template model's deformation under challenging body articulations based on 2D image observations. Our method outperforms state-of-the-art methods on an in-the-wild human video dataset 3DPW. Moreover, we demonstrate its efficacy in robustness and generalizability on videos from iPER datasets.