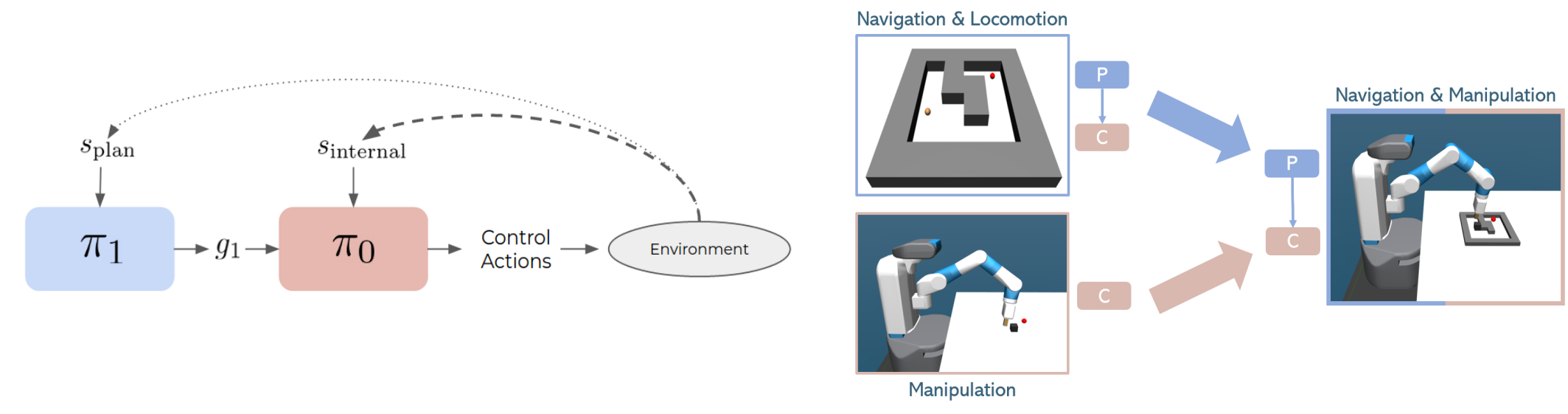
Left) Our 2-layer Hierarchical Reinforcement Learning architecture. The planning layer receives information crucial for planning and provides subgoals to the lower level. A goal-conditioned control policy learns to reach the target given the agent's internal state. Right) Showing the decompositionality of our approach, the Planning policy of simple agent is transferred to a more complex Control policies. In this example, the planner of a simple ball is combined with the control of a robot manipulator.
Abstract
We present HiDe, a novel hierarchical reinforcement learning architecture that successfully solves long horizon control tasks and generalizes to unseen test scenarios. Functional decomposition between planning and low-level control is achieved by explicitly separating the state-action spaces across the hierarchy, which allows the integration of task-relevant knowledge per layer. We propose an RL-based planner to efficiently leverage the information in the planning layer of the hierarchy, while the control layer learns a goal-conditioned control policy. The hierarchy is trained jointly but allows for the composition of different policies such as transferring layers across multiple agents. We experimentally show that our method generalizes across unseen test environments and can scale to tasks well beyond 3x horizon length compared to both learning and non-learning based approaches. We evaluate on complex continuous control tasks with sparse rewards, including navigation and robot manipulation.
Video
Acknowledgments
This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme grant agreement No. StG-2016-717054.
