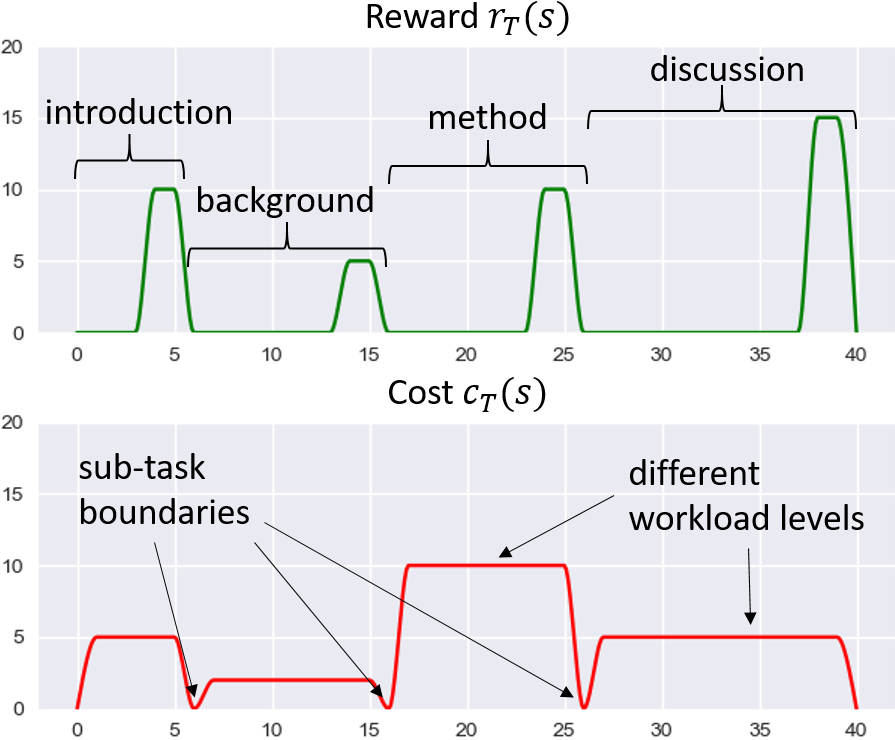
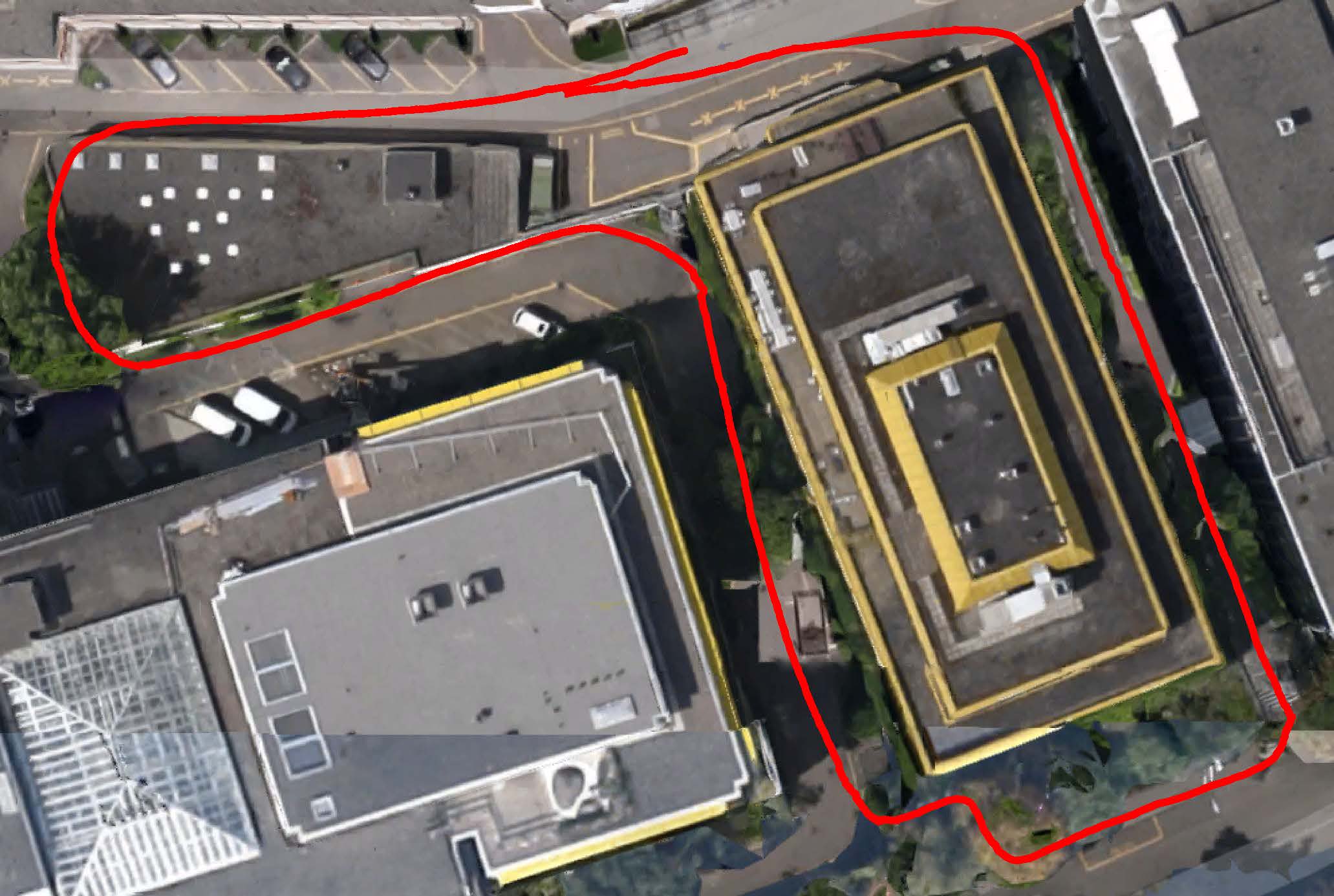
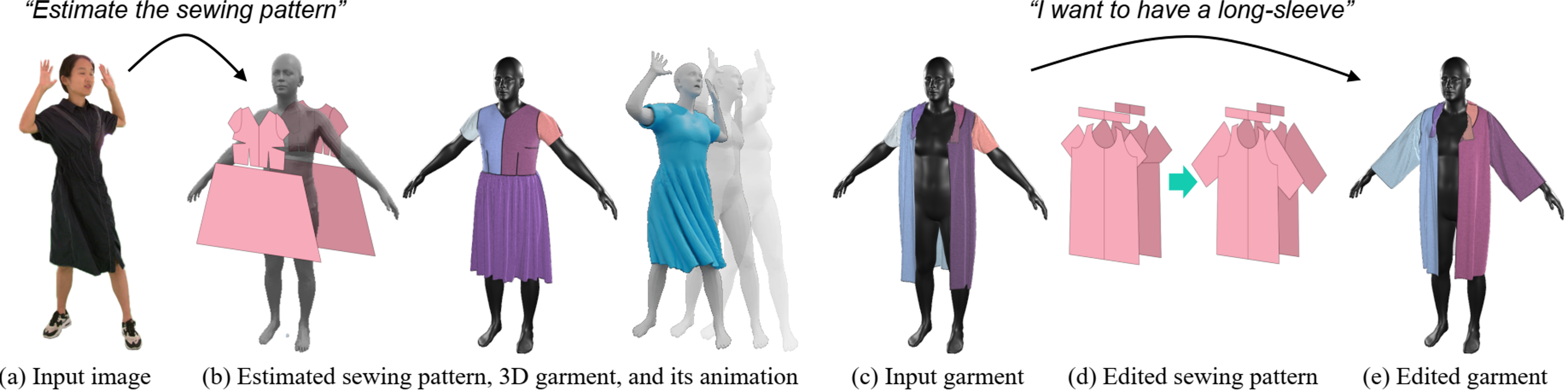
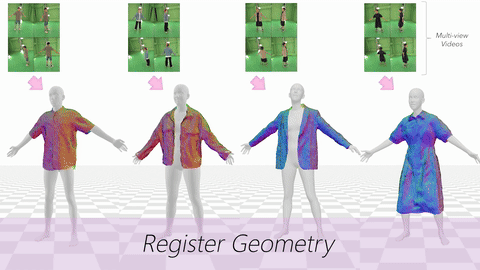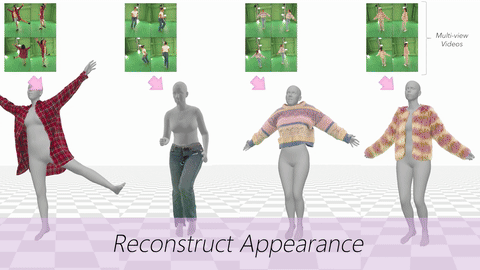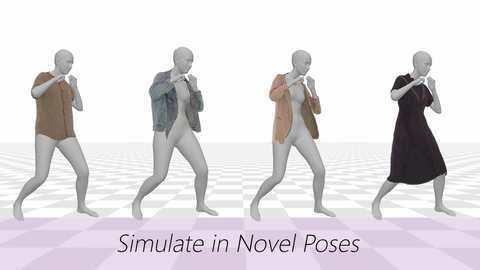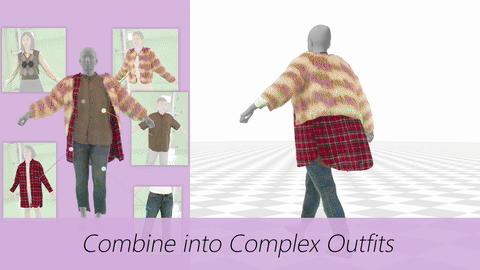
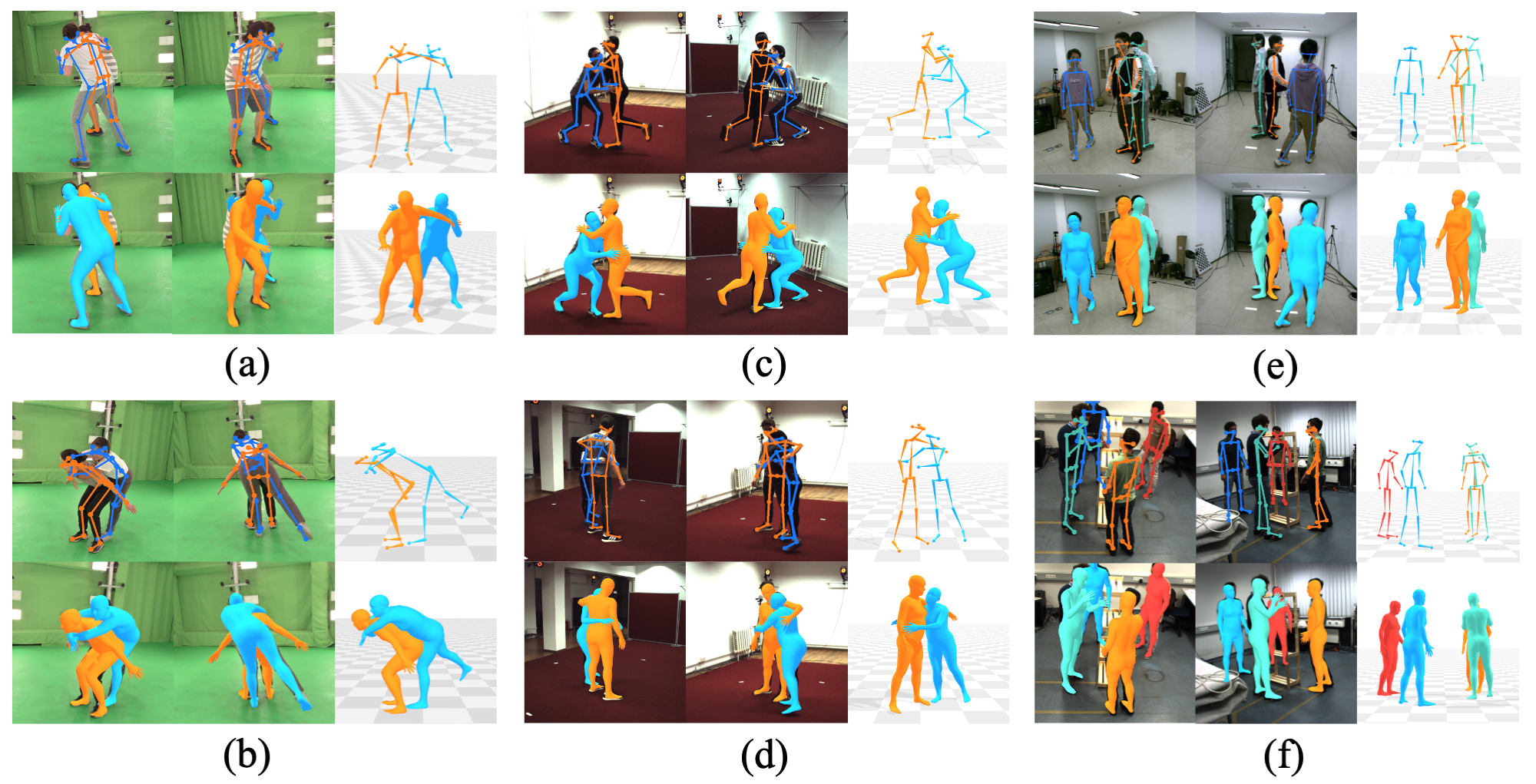
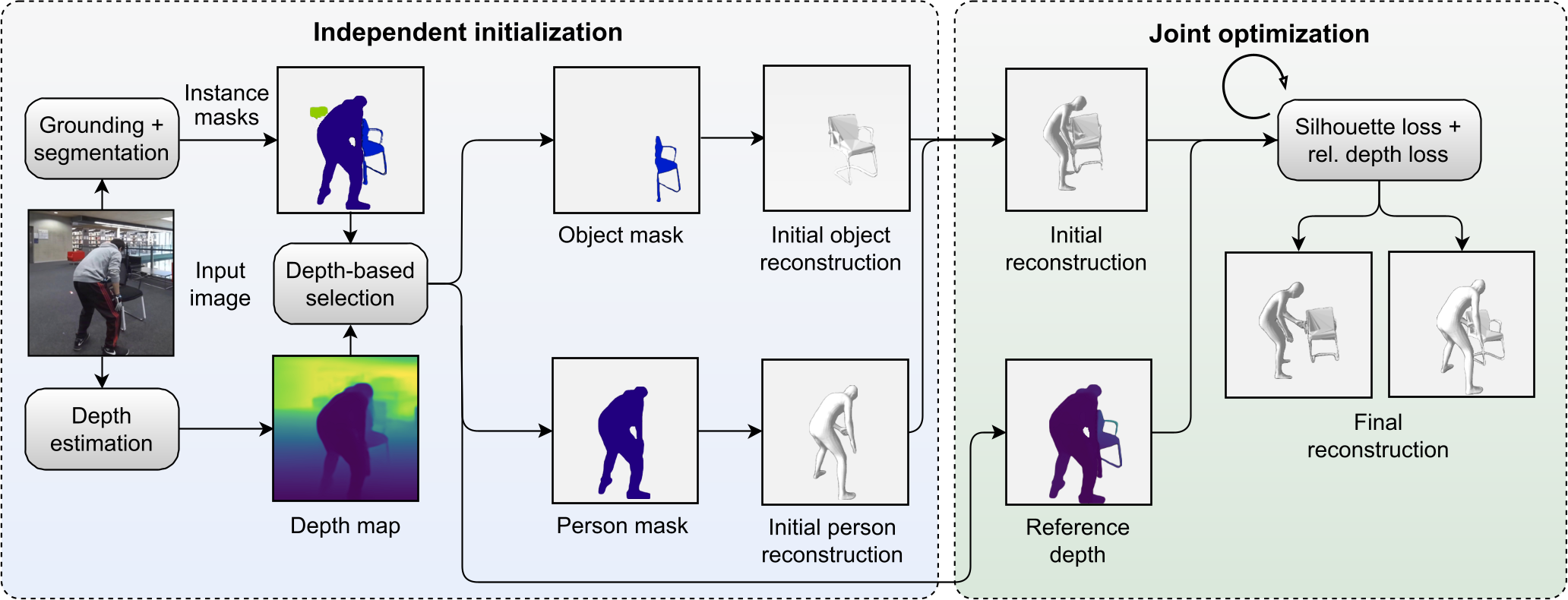
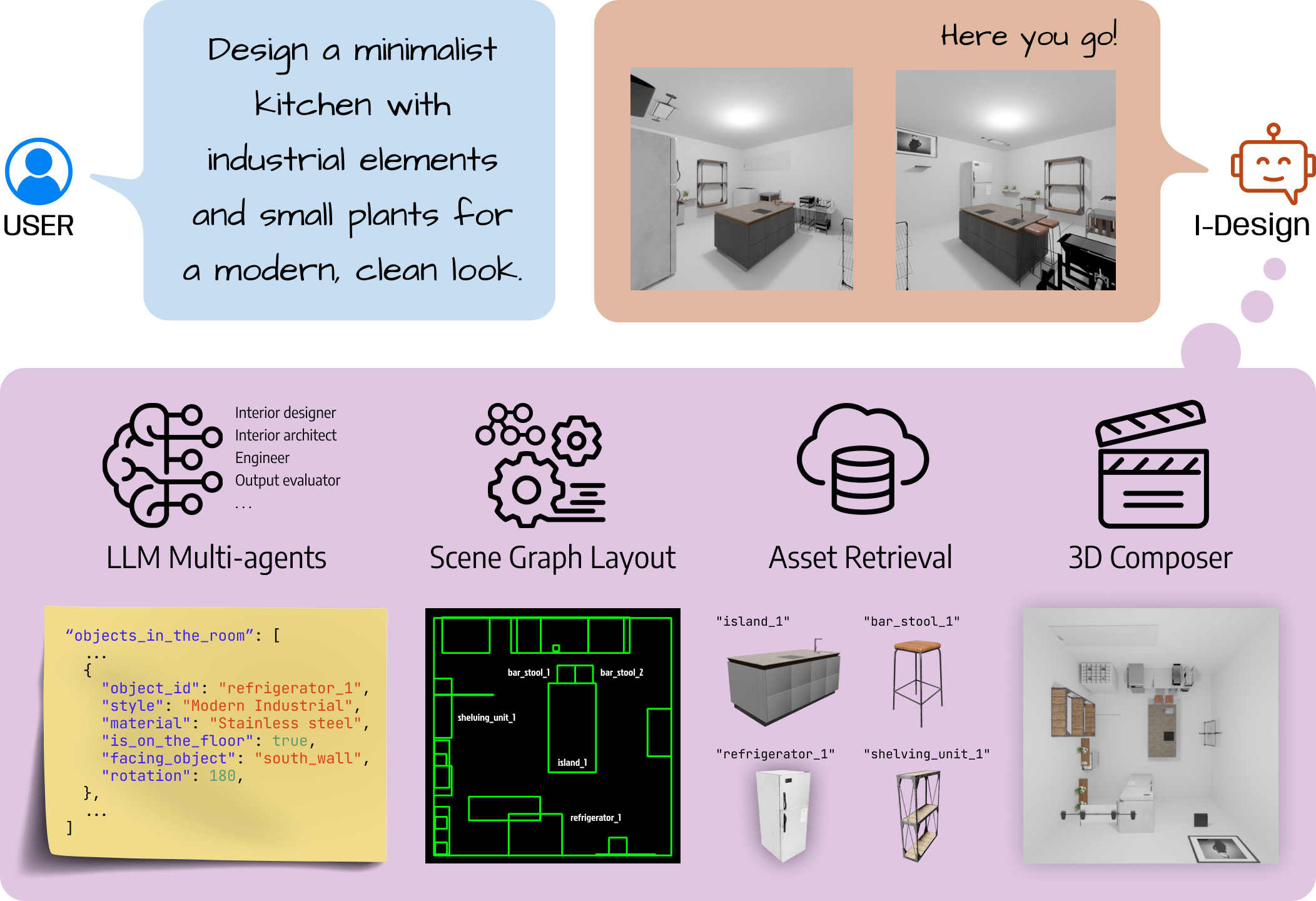
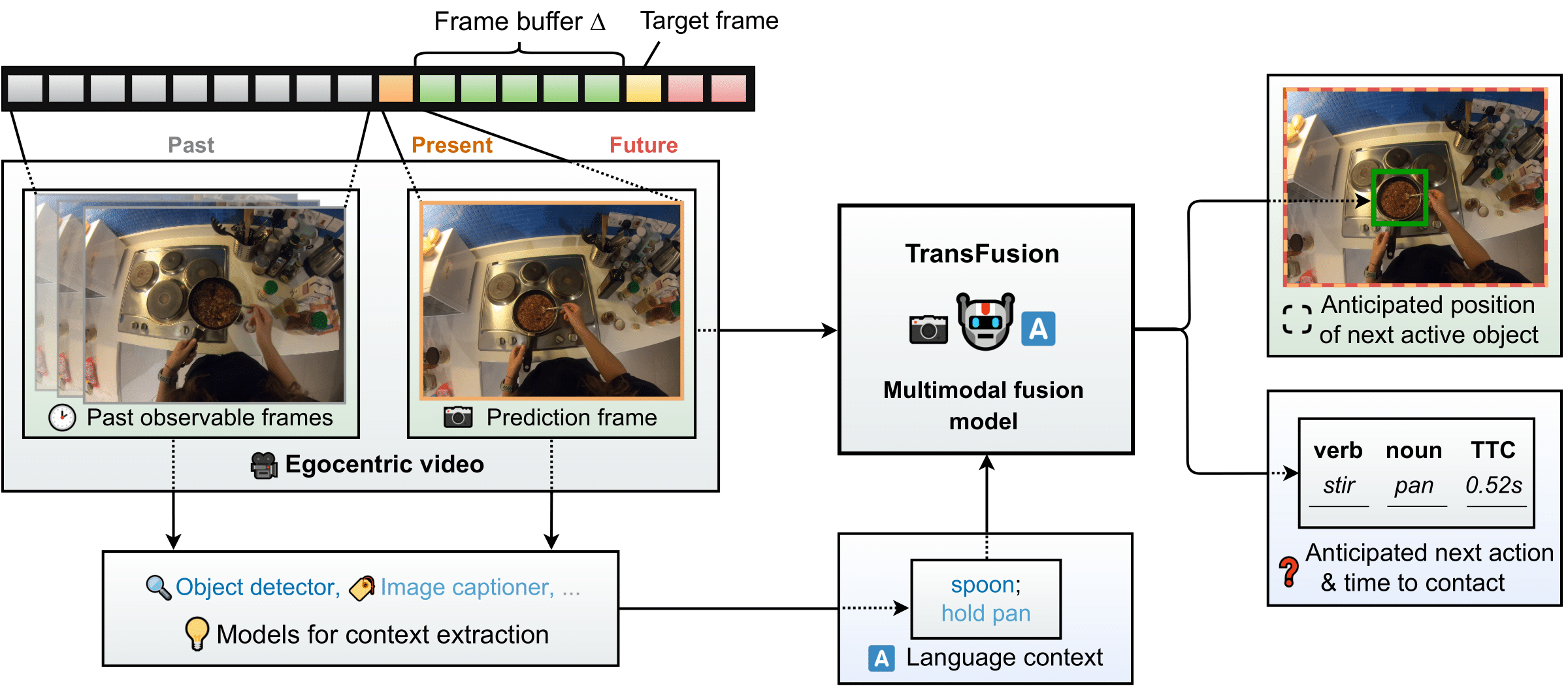
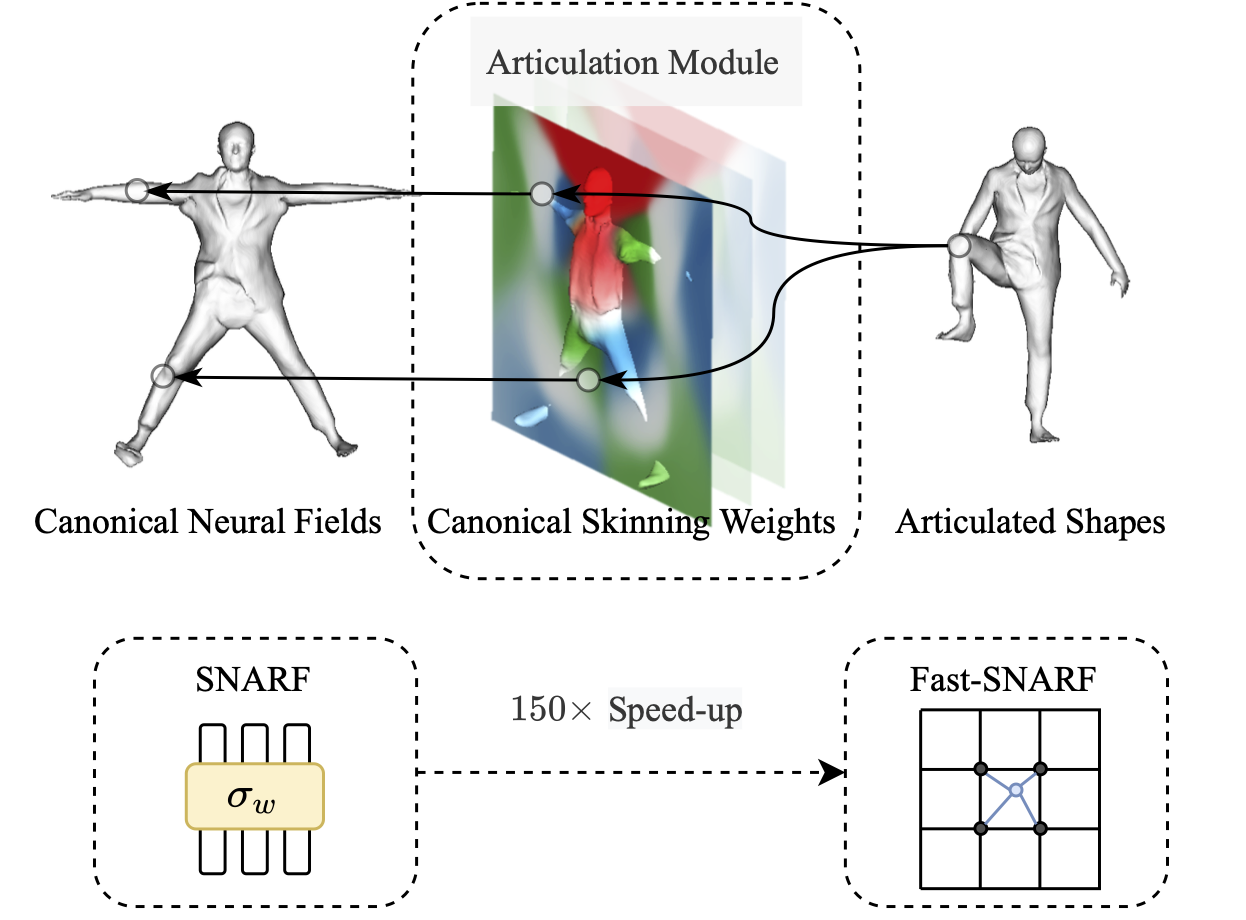
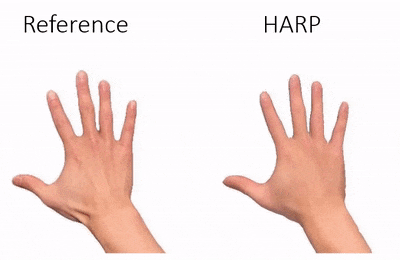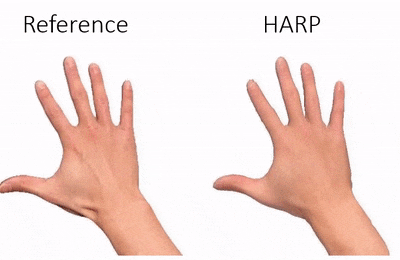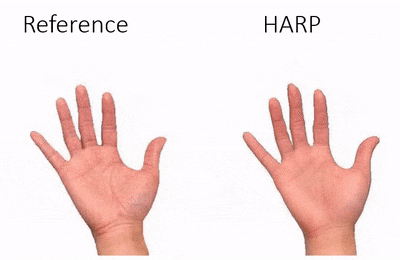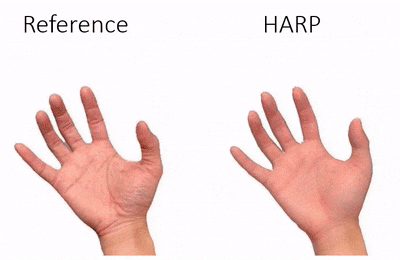
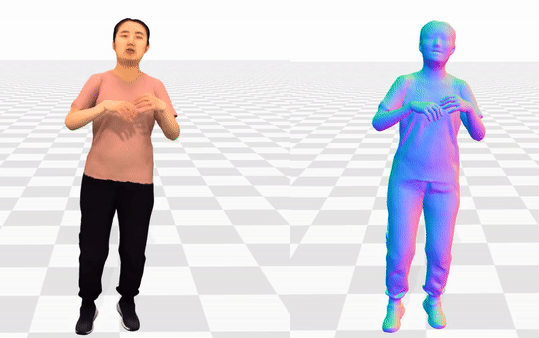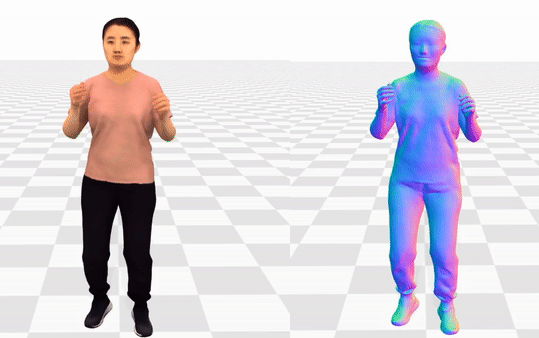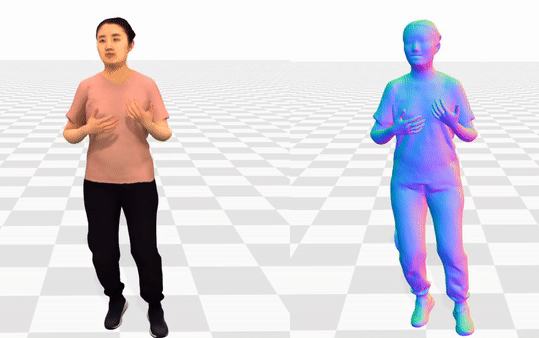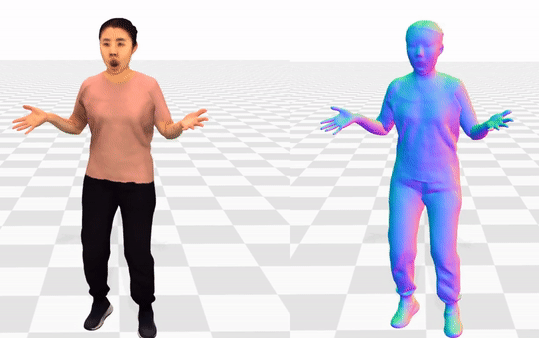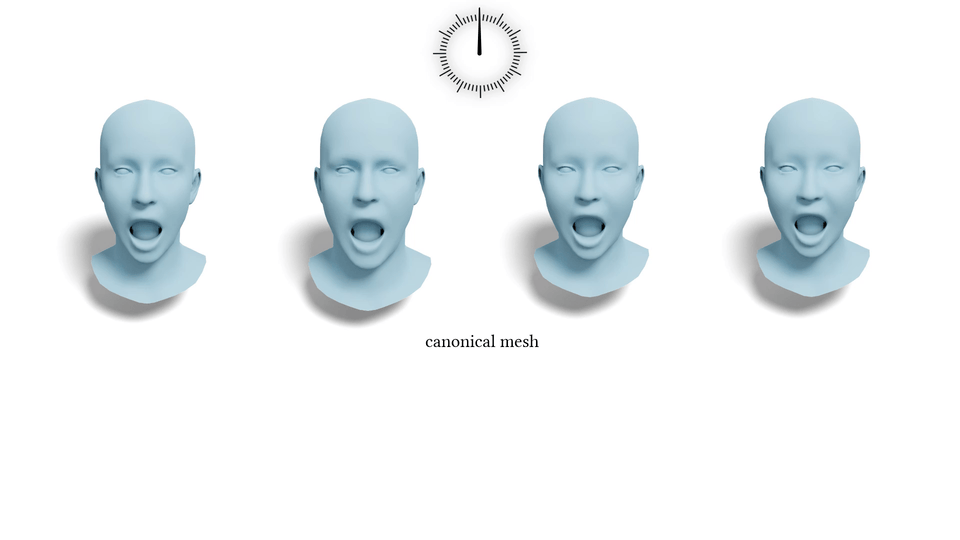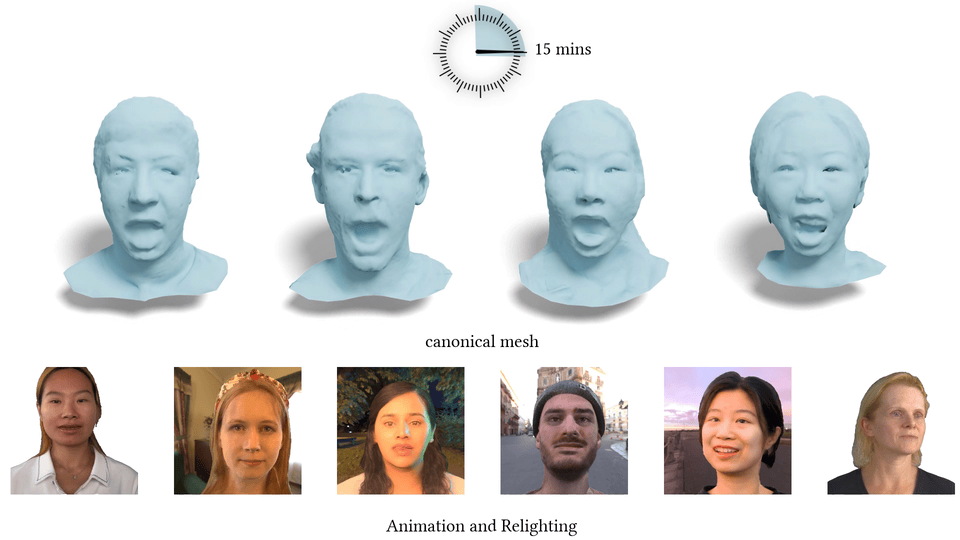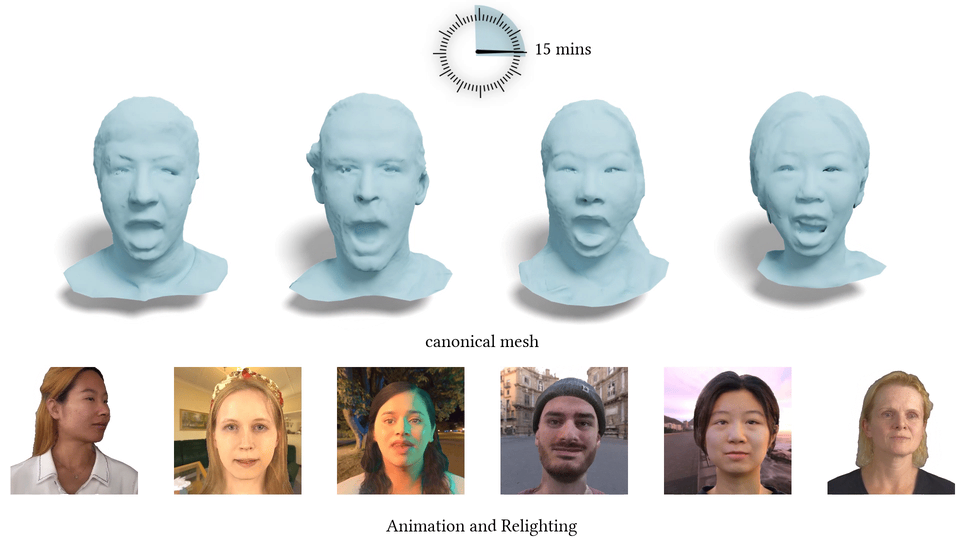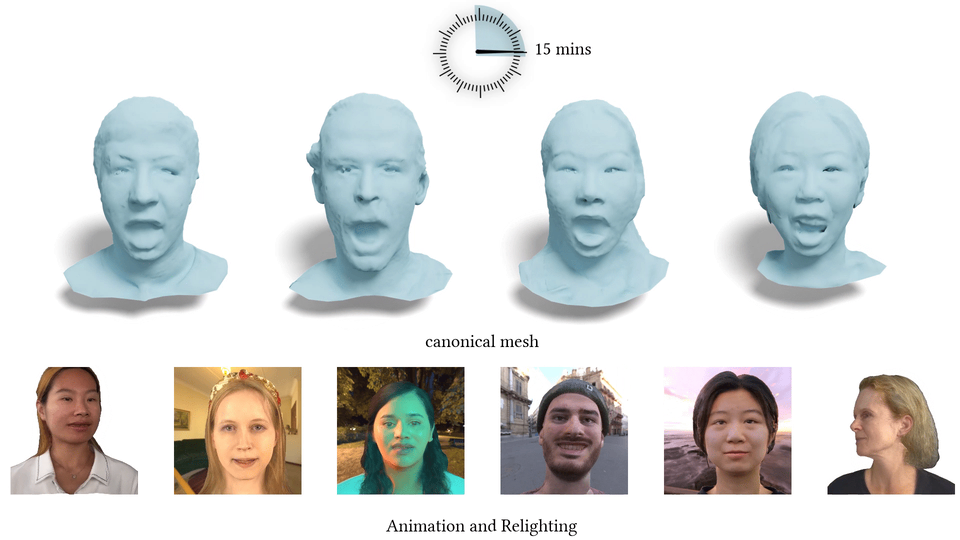Data & Code Dataset access might require filling out a form and is subject to approval. Data is for research purposes only. Data Cafca: High-quality Novel View Synthesis of Expressive Faces from Casual Few-shot Captures WorldPose: A World Cup Dataset for Global 3D Human Pose Estimation GraspXL: Generating Grasping Motions for Diverse Objects at Scale MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild 4D-DRESS: A 4D Dataset of Real-World Human Clothing With Semantic Annotations EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild Learning Locally Editable Virtual Humans X-Avatar: Expressive Human Avatars Hi4D: 4D Instance Segmentation of Close Human Interaction Human-Aware Object Placement for Visual Environment Reconstruction IM Avatar: Implicit Morphable Head Avatars from Videos SPEC: Seeing People in the wild with an Estimated Camera EM-POSE: 3D Human Pose Estimation from Sparse Electromagnetic Trackers Towards End-to-end Video-based Eye-Tracking Learning to Assemble: Estimating 6D Poses for Robotic Object-Object Manipulation Hierarchical Reinforcement Learning Explains Task Interleaving Behavior Deep Inertial Poser: Learning to Reconstruct Human Pose from Sparse Inertial Measurements in Real Time Cross-modal deep variational hand pose estimation Duo-VIO: Fast, Light-weight, Stereo Inertial Odometry In-air Gestures Around Unmodified Mobile Devices Code HyperGaussians: High-Dimensional Gaussian Splatting for High-Fidelity Animatable Face Avatars Gaussian Wardrobe: Compositional 3D Gaussian Avatars for Free-Form Virtual Try-on ChatGarment: Garment Estimation, Generation and Editing via Large Language Models PromptHMR: Promptable Human Mesh Recovery SurFhead: Affine Rig Blending for Geometrically Accurate 2D Gaussian Surfel-based Head Avatars Gaussian Garments: Reconstructing Simulation-ready Clothing with Photorealistic Appearance from Multi-view Video Grasping Diverse Objects with Simulated Humanoids VOODOO XP: Expressive One-Shot Head Reenactment for VR Telepresence EgoHDM: An Online Egocentric-Inertial Human Motion Capture, Localization, and Dense Mapping System DiffH2O: Diffusion-Based Synthesis of Hand-Object Interactions from Textual Descriptions ReLoo: Reconstructing Humans Dressed in Loose Garments from Monocular Video in the Wild HSR: Holistic 3D Human-Scene Reconstruction from Monocular Videos GraspXL: Generating Grasping Motions for Diverse Objects at Scale Human Hair Reconstruction with Strand-Aligned 3D Gaussians AvatarPose: Avatar-guided 3D Pose Estimation of Close Human Interaction from Sparse Multi-view Videos ROMEO: Revisiting Optimization Methods for Reconstructing 3D Human-Object Interaction Models From Images I-Design: Personalized LLM Interior Designer ContourCraft: Learning to Resolve Intersections in Neural Multi-Garment Simulations WANDR: Intention-guided Human Motion Generation VOODOO 3D: Volumetric Portrait Disentanglement for One-Shot 3D Head Reenactment Summarize the Past to Predict the Future: Natural Language Descriptions of Context Boost Multimodal Object Interaction Anticipation MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild HOLD: Category-agnostic 3D Reconstruction of Interacting Hands and Objects from Video HAAR: Text-Conditioned Generative Model of 3D Strand-based Human Hairstyles SiTH: Single-view Textured Human Reconstruction with Image-Conditioned Diffusion 4D-DRESS: A 4D Dataset of Real-World Human Clothing With Semantic Annotations Dream-in-4D: A Unified Approach for Text- and Image-guided 4D Scene Generation HUGS: Human Gaussian Splats ArtiGrasp: Physically Plausible Synthesis of Bi-Manual Dexterous Grasping and Articulation Physically Plausible Full-Body Hand-Object Interaction Synthesis HMP: Hand Motion Priors for Pose and Shape Estimation from Video FLARE: Fast Learning of Animatable and Relightable Mesh Avatars AG3D: Learning to Generate 3D Avatars from 2D Image Collections EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild Fast-SNARF: A Fast Deformer for Articulated Neural Fields Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-supervised Scene Decomposition PointAvatar: Deformable Point-based Head Avatars from Videos HOOD: Hierarchical Graphs for Generalized Modelling of Clothing Dynamics HARP: Personalized Hand Reconstruction from a Monocular RGB Video Learning Human-to-Robot Handovers from Point Clouds GazeNeRF: 3D-Aware Gaze Redirection with Neural Radiance Fields Learning Locally Editable Virtual Humans ARCTIC: A Dataset for Dexterous Bimanual Hand-Object Manipulation X-Avatar: Expressive Human Avatars InstantAvatar: Learning Avatars from Monocular Video in 60 Seconds Hi4D: 4D Instance Segmentation of Close Human Interaction TempCLR: Reconstructing Hands via Time-Coherent Contrastive Learning SFP: State-free Priors for Exploration in Off-Policy Reinforcement Learning gDNA: Towards Generative Detailed Neural Avatars D-Grasp: Physically Plausible Dynamic Grasp Synthesis for Hand-Object Interactions Human-Aware Object Placement for Visual Environment Reconstruction IM Avatar: Implicit Morphable Head Avatars from Videos A Spatio-temporal Transformer for 3D Human Motion Prediction Human Performance Capture from Monocular Video in the Wild Render In-between: Motion Guided Video Synthesis for Action Interpolation VariTex: Variational Neural Face Textures SPEC: Seeing People in the wild with an Estimated Camera SNARF: Differentiable Forward Skinning for Animating Non-Rigid Neural Implicit Shapes PeCLR: Self-Supervised 3D Hand Pose Estimation from monocular RGB via Equivariant Contrastive Learning Shape-aware Multi-Person Pose Estimation from Multi-view Images EM-POSE: 3D Human Pose Estimation from Sparse Electromagnetic Trackers PARE: Part Attention Regressor for 3D Human Body Estimation Learning To Regress Bodies From Images Using Differentiable Semantic Rendering Improved Learning of Robot Manipulation Tasks via Tactile Intrinsic Motivation Learning Functionally Decomposed Hierarchies for Continuous Control Tasks With Path Planning CoSE: Compositional Stroke Embeddings Self-Learning Transformations for Improving Gaze and Head Redirection Convolutional Autoencoders for Human Motion Infilling Spatial Attention Improves Iterative 6D Object Pose Estimation ETH-XGaze: A Large Scale Dataset for Gaze Estimation under Extreme Head Pose and Gaze Variation Category Level Object Pose Estimation via Neural Analysis-by-Synthesis Human Body Model Fitting by Learned Gradient Descent Towards End-to-end Video-based Eye-Tracking Detecting Relevance during Decision-Making from Eye Movements for UI Adaptation VIBE: Video Inference for Human Body Pose and Shape Estimation Learning to Assemble: Estimating 6D Poses for Robotic Object-Object Manipulation Hierarchical Reinforcement Learning Explains Task Interleaving Behavior Content-Consistent Generation of Realistic Eyes with Style Structured Prediction Helps 3D Human Motion Modelling Photo-Realistic Monocular Gaze Redirection Using Generative Adversarial Networks Few-Shot Adaptive Gaze Estimation Monocular Neural Image Based Rendering with Continuous View Control Context-Aware Online Adaptation of Mixed Reality Interfaces Unpaired Pose Guided Human Image Generation Video-based Prediction of Hand-grasp Preshaping with Application to Prosthesis Control Demonstration-Guided Deep Reinforcement Learning of Control Policies for Dexterous Human-Robot Interaction STCN: Stochastic Temporal Convolutional Networks Deep Inertial Poser: Learning to Reconstruct Human Pose from Sparse Inertial Measurements in Real Time Deep Pictorial Gaze Estimation Cross-modal deep variational hand pose estimation Learning to Find Eye Region Landmarks for Remote Gaze Estimation in Unconstrained Settings DeepWriting: Making Digital Ink Editable via Deep Generative Modeling AdaM: Adapting Multi-User Interfaces for Collaborative Environments in Real-Time Plan3D: Viewpoint and Trajectory Optimization for Aerial Multi-View Stereo Reconstruction Learning human motion models for long-term predictions Guiding InfoGAN with Semi-Supervision Duo-VIO: Fast, Light-weight, Stereo Inertial Odometry