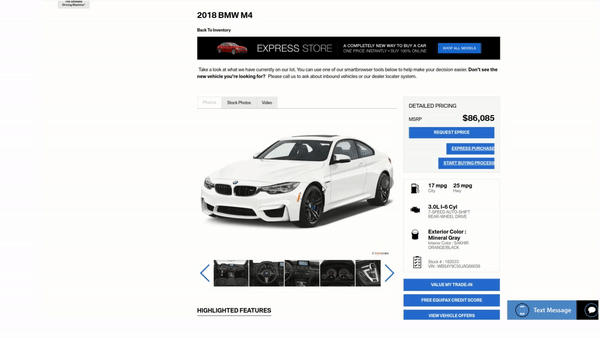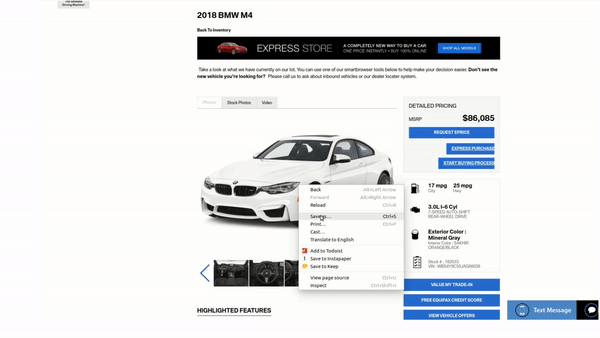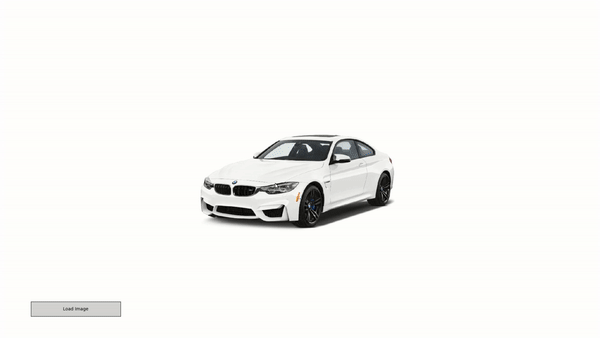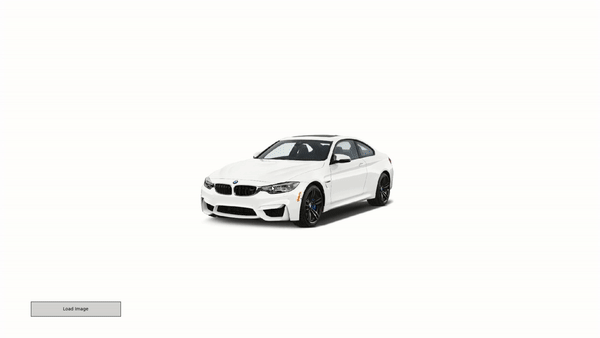
Our model can generalize well to unseen data due to a novel depth-based warping approach. In this example a user downloads an _unseen_ image from the internet and our system allows to manipulate it in 3D with continuous view control. The process takes 50ms per frame on a Titan X GPU, which allows for real time rendering of synthetized views. Notably, our model was trained on synthetic objects taken from the shapenet dataset only and has never seen images of real objects during training.
Abstract
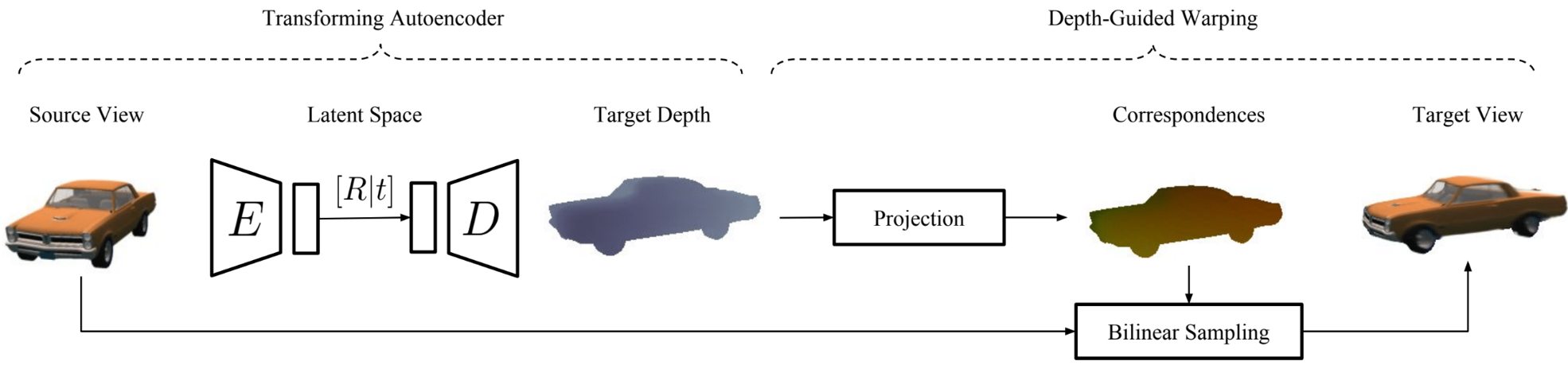
We present an approach that learns to synthesize high-quality, novel views of 3D objects or scenes, while providing fine-grained and precise control over the 6-DOF viewpoint. The approach is self-supervised and only requires 2D images and associated view transforms for training. Our main contribution is a network architecture that leverages a transforming auto-encoder in combination with a depth-guided warping procedure to predict geometrically accurate unseen views. Leveraging geometric constraints renders direct supervision via depth or flow maps unnecessary. If large parts of the object are occluded in the source view, a purely learning based prior is used to predict the values for dis-occluded pixels. Our network furthermore predicts a per-pixel mask, used to fuse depth-guided and pixel-based predictions. The resulting images reflect the desired 6-DOF transformation and details are preserved. We thoroughly evaluate our architecture on synthetic and real scenes and under fine-grained and fixed-view settings. Finally, we demonstrate that the approach generalizes to entirely unseen images such as product images downloaded from the internet.
Accompanying video
Gallery

Our method also generalizes to unseen natural scenes. Here we provide another application example, in which a user may explore the surroundings of a single image in 3D. In this case our model was trained on the KITTI dataset and the source view stems from an online mapping service.